Schema’yı tanımadan önce Yapılandırılmış Veri(Structred Data) ve Veri Yapılandırma(Data Markup) terimlerini bilmek gerekir.
Yapılandırılmış Veri(Structred Data) aslında tam anlamıyla arama motorlarının anlayamadığı web sayfası içeriklerinin yapılandırılarak arama motorlarının tanımlayabileceği şekle gelmiş halidir.
Web sitesi geliştiricilerin kullandığı HTML kodları ve etiketleri sadece sayfaya bir düzen ve içerik verir. Arama motoru bu içerikleri anlayabilecek kapasitede çalışan sistemler değillerdir.
Schema.org bize yardımcı olacak çeşitli düzenler sağlıyor ve öncü arama motorları da bu düzen çok stabil ve aktif çalıştığı için bu avantajları destekliyor. Bu arama motorları şunlar “Google, Microsoft, Yandex ve Yahoo!” olarak genelleme yapabiliriz. Tabi bu arama motorları bununla kısıtlı değil diğer çoğu arama motoru da buna destek veriyor.
Schema.org bize 3 tane Yapılandırılmış Veri Çözümleme Araçları(Structred Data Encoding Methods) ile yazım imkanı sunuyor. Bunlar ise şunlardan ibaret : “Microdata, RDFa, JSON-LD”. Bu araçlar ile WEB sitelerde belirtmek istediğimiz kategorideki veriyi ve bu verinin içeriklerini tam olarak arama motorlarına tam olarak aktarabiliriz.
Gelin bu çözümleme araçları ile birkaç örnek inceleyelim.
Microdata, HTML5 ile tanıtılan bir etiketler topluluğudur. Temel amacı Schema.org genel tanımında anlattığım gibi siteyi temel olarak Machine-Readable(Makine-Okuyabilir) hale getirebilen bir etiketler topluluğudur. Örneğin microdata ile tarayıcıya, “Bu filmin yazarı, yönetmeni, prodüktörü işte bu kişilerdir.” diyebiliyoruz.
Artık biraz kod görmemizin zamanı geldi örneğin aşağıdaki film tanıtım ‘div’ etiketi microdata
kullanılmadan oluşturulmuştur.

Burada bizim gördüğümüz ‘Avatar’ filmini kimin yaptığını ve ona ait fragmanı konu alan bir div bloğu görüyoruz fakat bunu arama motoru bir film olarak algılamıyor ve karşımıza bu film ile ilgili detayları çıkartmıyor. Arama motorunun burada tek gördüğü şey bir yazı bütünü.
Gelin bir de bunu arama motoruna tanıtılmış ve bir film olarak belirtilmiş halini görelim.

Burada ‘div’ etiketinin içine property(özellik) olarak yerleştirdiğimiz itemscope ve itemtype arama motoruna bu etiketi tanıtıyor.
‘itemscope’ adlı property bize bu etiket hakkında bilgi vericeğimizi belirtiyor ve ardından gelen ‘ ‘itemtype’ bu etiketin aslında bir filmi anlattığını söyleyecek kısım.
Hadi gelin bu bloğu biraz daha detaylandırıp filmin adını, türünü, yönetmenin adını ve fragmanının hangi objeyle ilgili olduğunu belirtelim.
Yukarıda gördüğünüz ‘itemprop’ isimli property bize o etiketin bu cismin hangi özelliği olduğunu anlatmaya yarıyor.
Örneğin
etiketi içindeki itemprop=’name’ olarak gözüken kısım bize Avatar adlı metinin bu filmin ismi olduğunu anlatıyor.
Örneğin 3. Satıra bakalım.
James Cameron
Buradaki ‘director’ arama motoruna bu filmin yönetmeninin James Cameron olduğunu anlatan kısımdır.
Yukarıda filmin yöneticisini birlikte tanımlamıştık ve arama motorları artık bu filmin bir yöneticisi olduğunu biliyor.
Fakat en başta bahsettiğim gibi bilgisayarlar hiç bir şey bilmez ve ne yazarsak onu okurlar.
Şimdi gelin bu yönetmenin bir insan olduğunu microdata ile anlatalım.

Az önce oluşturduğumuz etiketini
etiketi ile sardık ve yine aynı şekilde itemscope ve itemtype adlı property verdik.
itemtype=’http://schema.org/Person’ olarak yazdığımız yerde
artık bir insan olarak tanımlandı.
Bunun eşliğinde ise alttaki özelliğini de kullanabilir hale geldik.
Çünkü artık bir insan olduğunu söylediğimiz
etiketinin artık bir doğum günü olabilir ve bunu da “August 16, 1954” olarak belirtebildik.
Örneğin çoğunluğunu bitirdik gelin bir de diğer Veri Çözümleme Tekniklerine bakalım.
RDFa ile veri işaretleme yöntemi çok yaygın ve popüler olmasa da yine de kullanılan bir yöntemdir.
Genel kullanım olarak “Microdata” ya çok benzeyen bir yapısı vardır. Aynı şekilde belirtmek istediğiniz özellikleri ve başlıkları etiketlerin içine property olarak yazarsınız.
Alttaki örnekte aldığımız parent olarak kullandığımız
etiketi bizim ana yapımızı içinde saklayacağımız yapı olduğu için “data-vocabulary” adlı özelliği bu nesneye olarak olarak tanımladık ve oluşturucağımız review elementini bunun içine yazıcaz.
Hadi örneği biraz inceleyelim.

İlk satır’a nasıl bir düzende yazılıyor anlamak için bir bakalım.
L’Amourita Pizza
Microdata’da uyguladığımız sistemdeki gibi property kullandık ve bu cismin aslında bir itemreviewed olduğunu söyledik. Başlıkta ne gözükeceğine dair yazdığımız bu property başlıkta
“L’Amourita Pizza” olarak görmemizi sağlayacak kısımdı.
Açıklama satırını inceleyelim.
Bu bloğun etiketlerin arasına yazdığınız her şey açıklama olarak saklanır sitenin arama esnasında bu şekilde bir görüntü açığa çıkar.
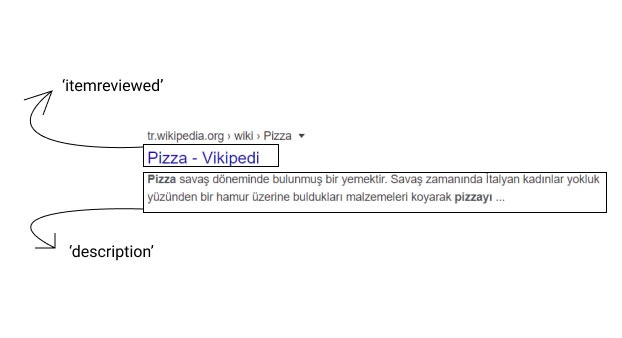
Diğer tüm özellikler de aynı Microdata yazarmış gibi yazılıp bu şekilde arama motoruna sunulabilir. Daha çok RDFa üzerinde durmayıp JSON-LD incelemesine geçebiliriz.
Aynı diğerleri gibi bir Veri Çözümleme Aleti olan JSON-LD Google’ın da tavsiyesiyle karşımıza çıkmaktadır. Şuan en çok kullanılan Veri Çözümleme Yöntemi olan JSON-LD işlerimizi bir yerde toplayıp daha dinamik ve güzel görünümlü bir data markup düzeni ile karşımıza çıkar.
Geçerli düzende yapılmış bir veri işaretleme ile arama motorlarında kendi kategorisinde en üstte görünen arama sonuçları elde edebilirsiniz.
script etiketi arasına yazılan bu işaretleme yöntemi bir JSON veri öbeği içinde saklanır ve Schema.org tarafında desteği ile bize diğerlerinden daha kolay bir kullanım sağlar.
Hadi gelin beraber bu işlemlerin nasıl işlediğini inceleyelim.

İlk baş görüldüğü gibi bir script etiketi oluşturup içinde kodlarımızı yazmaya başlıyacağız. Ama önce bu script’e bir type property vermemiz gerekiyor. Bu property “application/ld+json” olarak verilmiş bu sayede kodumuz çözümlenirken bu JSON-LD olarak tanınıcak.
Gelin bu etiketlemenin Google’da nasıl bir sonuca karşılık geldiğine bir bakalım.
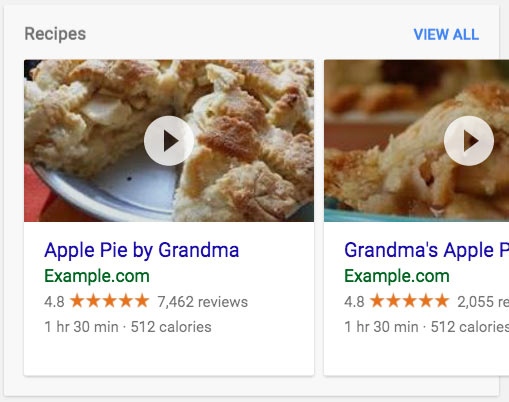
Yukarıdaki örnekte bir pasta ve tarifi hakkında çok sayıda bilgi depolayan bir JSON-LD markup görüyoruz.
Pastanın adı, hangi sitede paylaşıldığı, kaç kere görüntülendiği ve ortalama 5 üzerinden kaç puan aldığı, kaç saatte piştiği ve kaç kalori içerdiğini yukarıdaki JSON veri öbeğinde belirttiğimiz için karşımıza görseldeki gibi bir sonuç çıkıyor.
Hadi bu Data Markup’daki satırları inceleyelim ve ne işe yaradıklarını anlayalım.

Yukarıda gördüğünüz etikette microdatada verdiğimiz örnekteki gibi embed şekilde yazılan etiketlerimiz de bulunuyor. Bu etiketler ile objenin sitede kaç puan aldığını ‘ratingValue’ ile, kaç kişinin girip tarife baktığını ise ‘reviewCount’ kullanarak Google’da bu verilerin servis edilmesini sağlayabiliyoruz.
Genel olarak Data Markup işleminin bu şekilde döndüğü JSON-LD verilerinde temel mantık bu şekilde yürümekte. Eğer ki bu uçsuz bucaksız Veri Yapılandırma dünyasına giriş yapmak istiyorsanız dökümanlara şurdan ulaşabilirsiniz.
Kaynakça











Yorum Bildirin